
Last updated on

Within a mere twenty-four hours of Google’s Gemini becoming accessible to the public, an observant individual noticed that chats were inadvertently appearing in Google’s search results. Swiftly, Google addressed what seemed to be a breach of privacy. Surprisingly, the cause behind this occurrence is not as nefarious as initially presumed.
On the morning of Tuesday, February 13th, Google Gemini chats started disappearing from search results, with only three remaining visible. By the afternoon, the number of leaked chats dwindled further, with just a solitary search result displaying Gemini conversations.
Gemini provides a feature allowing users to generate a link to a publicly accessible version of a private chat.
It’s important to note that Google does not automatically convert private chats into webpages. Instead, users have the ability to create these chat pages themselves using a link located at the bottom of each chat.
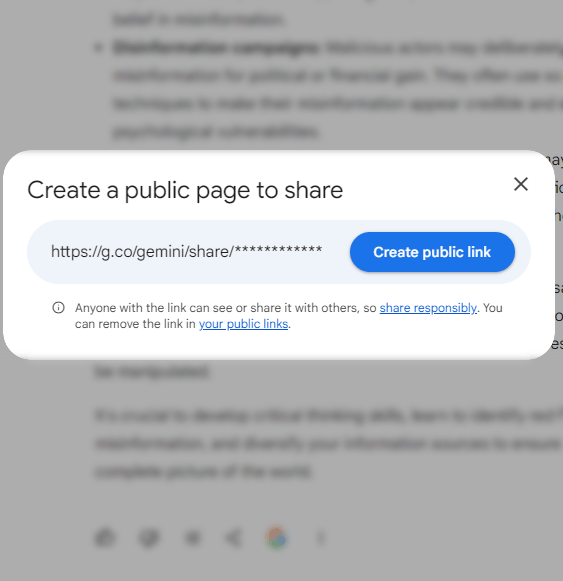
The apparent reason why the chat pages were crawled and indexed is likely due to Google’s oversight in implementing a robots.txt file in the root directory of the Gemini subdomain (gemini.google.com).
A robots.txt file serves as a means to control crawler activity on websites, allowing publishers to specify directives for search engine bots. These directives can include instructions to block specific crawlers, following commands standardized in the Robots.txt Protocol.
However, upon inspection at 4:19 AM on February 13th, I verified that a robots.txt file was indeed in place.

Continuing my investigation, I proceeded to check the Internet Archive to determine the duration for which the robots.txt file had been present. My findings revealed that the file had been in place since at least February 8th, coinciding with the announcement of the Gemini Apps.
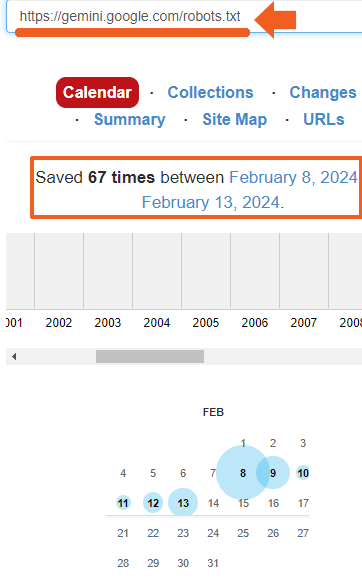
This implies that the apparent explanation for why the chat pages were crawled isn’t necessarily the accurate one; it’s merely the most apparent.
Despite the presence of a robots.txt file on the Google Gemini subdomain, which was intended to prevent web crawlers from both Bing and Google, how did these pages still get crawled and subsequently indexed?
There could be a publicly accessible link somewhere.
Less probable, but still feasible, is that they were stumbled upon via browsing history linked from cookies.
It’s more plausible that there are public links available.
I inquired with Bill Hartzer (@bhartzer) regarding this matter, and he unearthed a public link for one of the indexed pages.
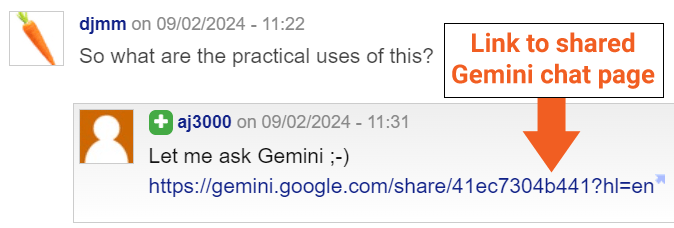
Now that we have more information, it appears highly probable that a public link led to the crawling and indexing of these Gemini Chat pages.
Bill Hartzer made the following observation:
“Despite the Gemini URL being blocked in the robots.txt file, a link to the Gemini URL was found in a blog comment, resulting in its indexing.
This underscores that Google may still index URLs blocked from crawling in the robots.txt file.
If Google truly aimed to prevent the indexing of the Gemini URL, they could allow crawling in the robots.txt file and include a noindex meta tag on the pages. Perhaps Google should adhere to its own recommendations in this scenario?”
Why did Google decide to stop indexing chat pages despite their public availability? Could it be that Google implemented a new policy instructing its search crawler to exclude pages within the /share/ folder from being indexed, regardless of their public linking?
Here’s the intriguing aspect that will captivate search enthusiasts curious about Google and Bing’s indexing methods.
Microsoft Bing’s search index reacted to the Gemini content in a distinct manner compared to Google search. While Google displayed three search results on the morning of February 13th, Bing only presented one result from the subdomain. The indexing process appeared to be somewhat arbitrary in terms of what was indexed and the extent of it.
Based on the provided facts:
Considering these points, the question arises: why did these pages start disappearing from the search results of both Google and Bing? One hypothesis is that the Google Gemini chat pages are of low quality and not relevant for longtail searches (e.g., site:gemini.google.com/share/). Therefore, there might not be a valid reason to display these pages in search results.
It’s worth noting that content blocked by robots.txt can still be discovered, crawled, and indexed, and if deemed useful, it can also rank in search results unless it’s considered irrelevant. This could potentially explain the situation.
Original news from SearchEngineJournal


