
Last updated on

Over the past decade, there has been a noticeable shift in the approach to SEO, transitioning from reliance on spreadsheets and anecdotal advice to a more data-centric methodology. This evolution is exemplified by the increasing number of SEO professionals embracing Python for analysis.
With Google rolling out numerous updates, such as the 11 seen in 2023, SEO experts are realizing the imperative of adopting a data-driven perspective, extending even to the internal link structures of website architectures.
In a prior piece, I discussed the potential for internal linking strategies to be guided by data analysis, offering Python scripts for statistically evaluating site architectures.
Beyond Python, leveraging data science methodologies can empower SEO professionals to uncover elusive patterns and pivotal insights, aiding in communicating the significance of content to search engine algorithms.
Data science serves as the nexus of coding, mathematics, and domain expertise, with SEO serving as our specific domain.
While proficiency in mathematics and coding, typically utilizing Python, remains crucial, SEO retains its paramount importance. The ability to pose pertinent questions to the data and intuitively assess whether the findings align with expectations are invaluable skills in this dynamic field.
Numerous websites follow a hierarchical structure akin to a Christmas tree, with the homepage positioned at the apex, signifying its utmost significance, while subsequent pages are arranged in descending order of importance across subsequent tiers.
For those inclined toward the intricacies of SEO, understanding the distribution of links across various viewpoints is crucial. This distribution can be effectively depicted through Python code, as demonstrated in a prior article, offering insights into:
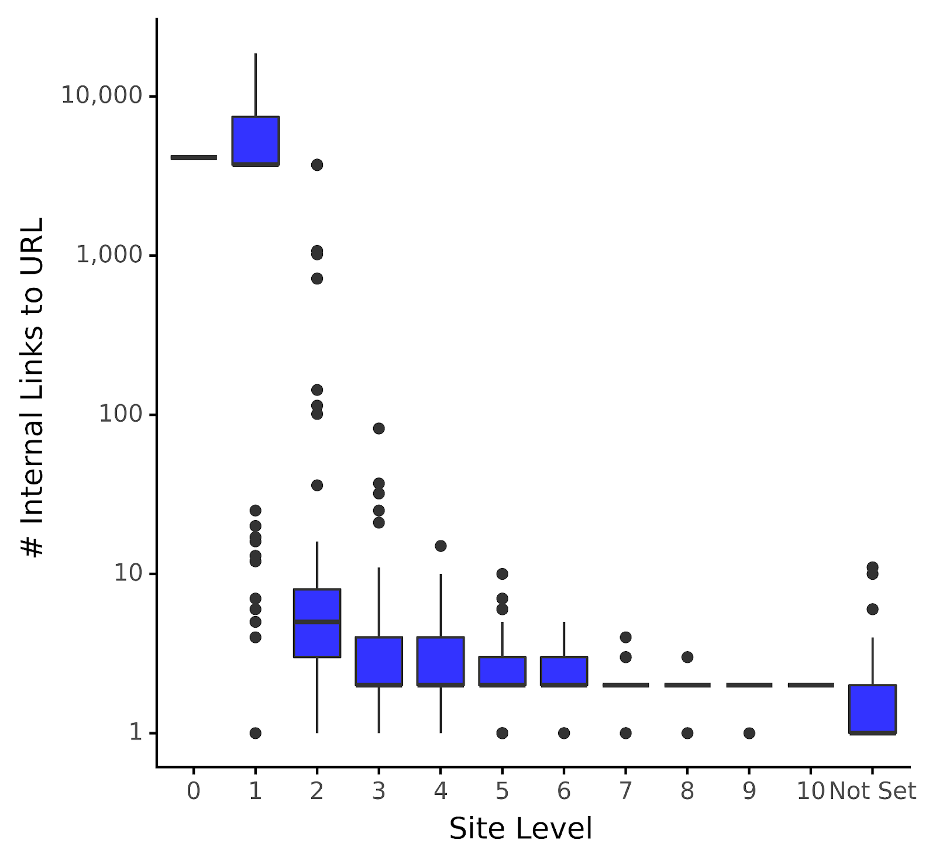
The boxplot serves as an effective tool for illustrating the typical number of links considered “normal” for different levels of a website. Within the plot, the blue boxes depict the interquartile range, encapsulating the 25th to 75th percentiles, where the majority (67% precisely) of inbound internal links are concentrated.
Visualize it akin to observing a bell curve from above, as if you were a bird soaring overhead. For instance, for pages situated two levels down from the homepage, the blue box denotes that approximately 67% of URLs possess between five and nine inbound internal links. This count is notably lower, albeit understandably so, compared to pages directly connected to the homepage.
The median line, intersecting the blue box, represents the 50th percentile or the middle value. Using the aforementioned example, for pages at site level 2, the median inbound internal links amount to 7, a staggering 5,000 times less than those at site level 1!
It’s worth noting that the median line may not be visible for all blue boxes due to data skewness, indicating that the data doesn’t conform to a normal distribution akin to a bell-shaped curve.
A data scientist lacking SEO expertise might opt to rebalance the distribution of internal links across pages based on site level. By analyzing the distribution of internal links to pages according to their respective site levels, they could identify pages falling below the median or the 20th percentile (quantile) for their site level. This observation might lead the data scientist to conclude that such pages require additional internal links.
However, this approach assumes that pages sharing the same level of depth from the homepage possess equal importance. Yet, this assumption may not hold true from a search value perspective. It fails to consider that certain pages at the same depth level may have substantially higher search demand than others.
Therefore, an optimal site architecture should prioritize pages with higher search demand over those with lower demand, irrespective of their default position in the hierarchy based on site level. This ensures that pages most likely to attract organic traffic receive sufficient internal linking support, enhancing their visibility and relevance in search results.
True Internal Page Rank (TIPR), as popularized by Kevin Indig, adopts a more sensible approach by incorporating external PageRank, derived from backlinks. In simple mathematical terms:
TIPR = Internal Page Rank x Page Level Authority of Backlinks
While the above formula is a simplified version of his metric, it offers a more practical and empirical means of assessing a page’s value within a website architecture. For those interested in computing this metric, please refer to the provided code.
Moreover, rather than applying this metric to site levels, it proves more instructive to apply it based on content type. For instance, when analyzing an ecommerce client, below is the distribution of TIPR by content type.
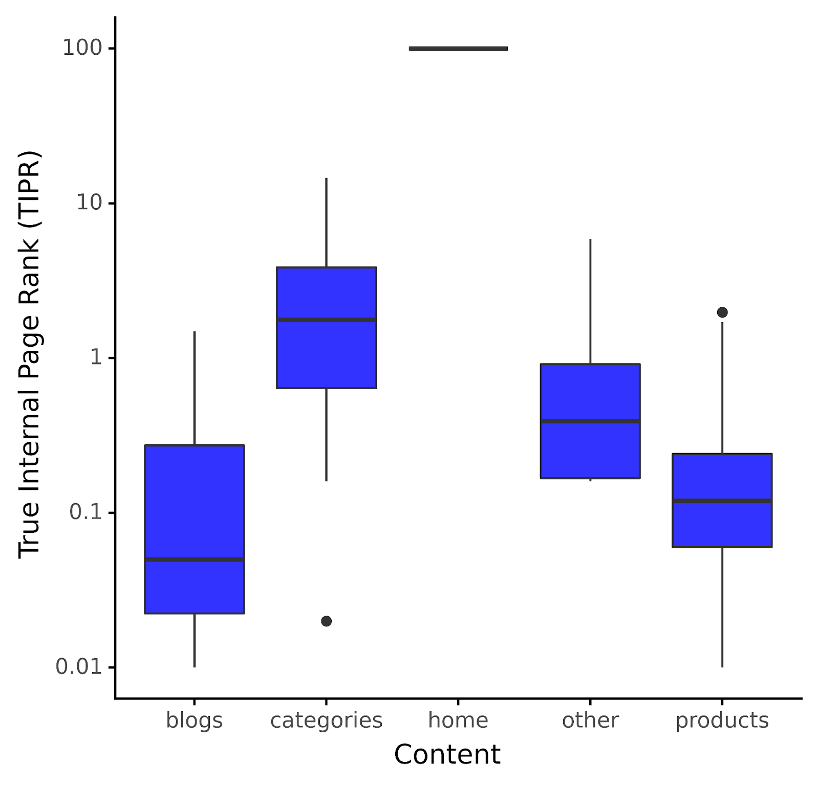
In the case of this online store, the median TIPR for categories content or Product Listing Pages (PLPs) is approximately two TIPR points.
Granted, TIPR may seem somewhat abstract, as its direct translation to the required amount of internal links isn’t straightforward.
Despite its abstract nature, TIPR remains a valuable construct for shaping site architecture.
For instance, if one were to identify categories underperforming relative to their rank position potential, a simple analysis might reveal PLP URLs falling below the 25th quantile. In such cases, one might consider seeking internal links from pages with a higher TIPR value.
Determining the appropriate number of links and their corresponding TIPR values would require further modeling, a topic deserving of exploration in a separate post.
Another crucial question to address is: which content merits higher rank positions?
Kevin also promoted a more enlightened approach of aligning internal link structures with conversion values, a strategy that many of you are hopefully already implementing for your clients; a stance with which I wholeheartedly concur.
A straightforward, albeit non-scientific, solution is to calculate the ratio of ecommerce revenue to TIPR, expressed as:
RIPR = Revenue / TIPR
This metric enables us to understand what typical revenue per page authority entails, as illustrated below.
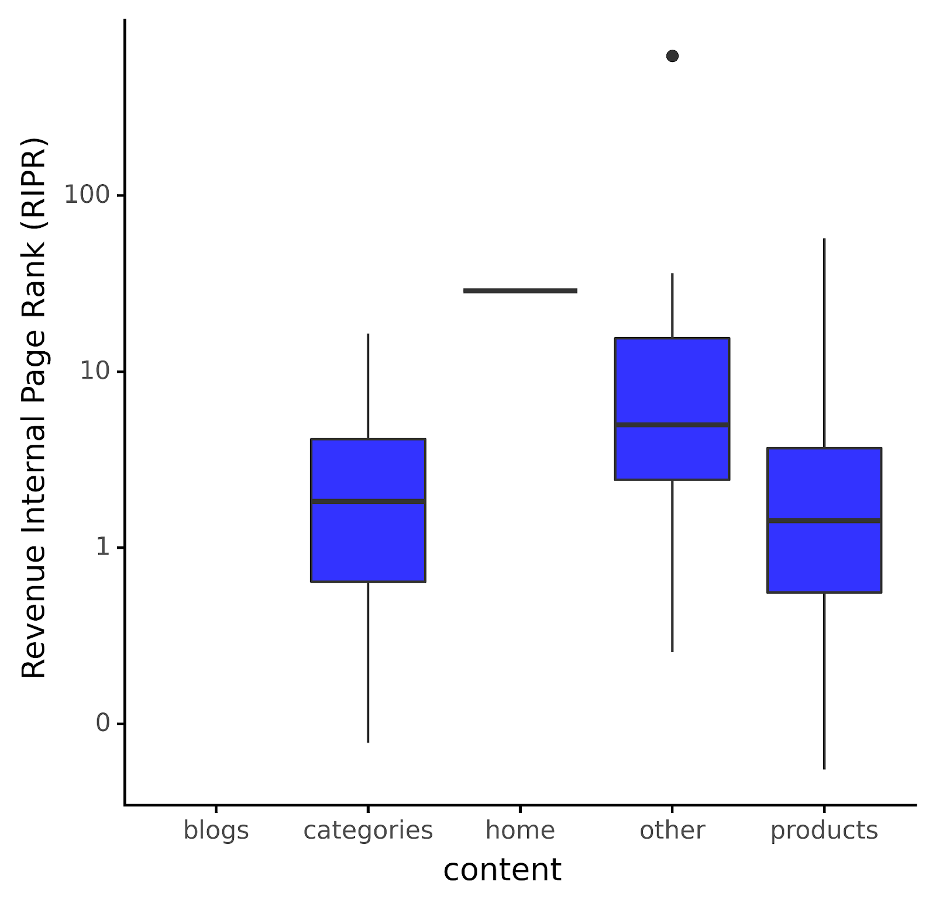
As depicted, the scenario undergoes a notable shift; blog content, for instance, lacks a box (i.e., distribution) since no revenue is associated with that content.
In practical terms, if we employ this model by content type, pages surpassing the 75th quantile (i.e., exceeding their blue box) for their respective content type should receive additional internal links.
Why? Because despite their high revenue, they exhibit low Page Authority, resulting in a high RIPR. Consequently, they warrant more internal links to align their importance closer to the median.
Conversely, pages with lower revenue but an excessive number of significant internal links will yield a lower RIPR. Therefore, reducing their internal links would enable higher revenue content to be prioritized by search engines, thus enhancing its significance.
RIPR operates under certain underlying assumptions, one being the proper setup of analytics revenue tracking to ensure that your model serves as the foundation for effective internal link recommendations.
Similar to TIPR, it’s essential to quantify the value of an internal link in RIPR in relation to its originating page.
These considerations precede the discussion of where to place internal links within the content itself.
Original news from SearchEngineJournal


