
Last updated on

Perplexity’s approach with its new Pages feature has sparked significant controversy among publishers, though the scale of the reaction may be exaggerated. The feature represents an intriguing case in the realm of user-directed AI content (UDC), diverging from traditional user-generated content (UGC).
Perplexity Pages enables users to craft detailed, aesthetically pleasing articles on diverse subjects. Users can transform a thread or a series of prompts into a comprehensive page focused on any topic.
Regular readers of Growth Memo quickly discern that this initiative serves as a growth tactic. Ideally, users generate AI-driven content capable of achieving high organic search rankings, thereby driving traffic to perplexity.ai and converting visitors into paying subscribers.
CEO Srinivas positions this strategy within Perplexity’s broader vision as an “information aggregator,” emphasizing a commitment to superior user experiences that effectively harness demand and optimize supply.
When examining the actual data, it becomes evident that the media’s reaction is disproportionately amplified compared to its actual impact. While constructive criticism is valid, it’s reasonable to expect Perplexity to make adjustments regarding attribution, adhere to web standards such as robots.txt protocols, and utilize official IPs similar to search engines.
Developer Ryan Knight clarified that Perplexity employs a headless browser for web crawling, masking its IP string during the process.
CEO Srinivas affirmed that Perplexity respects robots.txt directives and indicated that the masked IP originated from a third-party service. He also noted the evolving landscape of AI necessitating a new collaborative dynamic between content creators (publishers) and platforms like Perplexity.
However, from Perplexity’s perspective, the Pages feature represents only a minor contribution to its overall strategy and benefit.
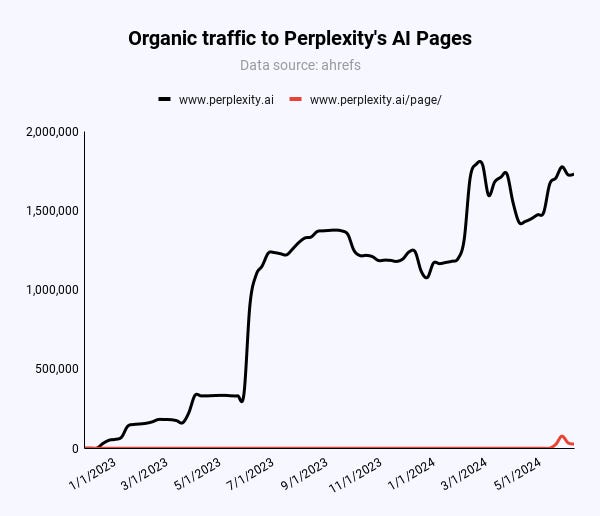
91% of organic traffic to perplexity.ai comes from branded terms like “perplexity.”
Out of 217,000 monthly visitors to Pages globally, only 47,000 (21.6%) arrive through organic, non-branded keywords.
In the US, this figure stands at 55% (20,000 out of 36,000). Despite this, Pages’ contribution to Perplexity’s organic traffic is minimal compared to the volume generated by branded terms.
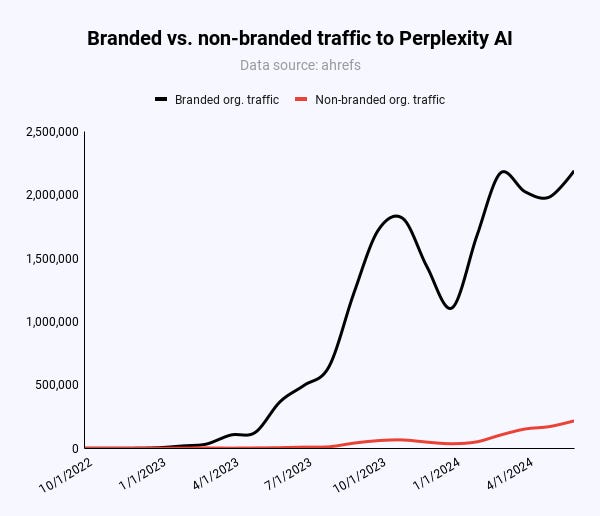
In reality, the majority of traffic to Perplexity originates from its brand recognition and word-of-mouth referrals. Interestingly, the recent media coverage may have benefited Perplexity more than it adversely affected it. Similarweb data indicates that the site has consistently achieved new all-time highs in traffic every day since January 2024.
Perplexity’s entire domain comprises just 950 pages, with Pages accounting for nearly 600 of them. Compared to giants like Wikipedia, which boasts 6.8 million articles in English alone, this number appears relatively small. However, as Pages gain more traction, stronger scalability effects are expected to emerge. Currently, Pages remains in its early stages as a beta feature.
Examining its performance, Pages rank in the top 3 search results for highly sought-after keywords like “was candy montgomery guilty” (with 600 monthly search volume). The most challenging keyword it holds the top position for is “when was the first bitcoin purchase” (Keyword Difficulty: 76, Monthly Search Volume: 30). This indicates that Pages still have significant ground to cover in terms of development and visibility.
A preliminary comparison using GoTranscript’s n=1 text similarity tool between Perplexity’s “bitcoin pizza day” page and its four referenced sources indicates minimal signs of plagiarism:

The issue of “missing” attribution appears to have been resolved, as illustrated in the following example.
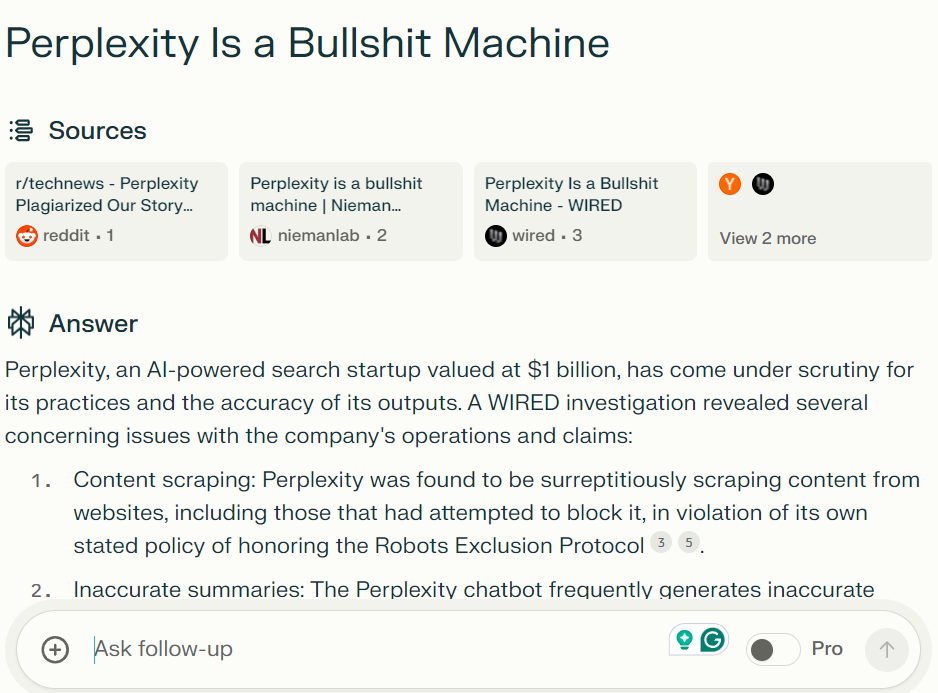
The analysis revealed instances where the chatbot closely echoed WIRED stories, occasionally summarizing them inaccurately and with minimal acknowledgment.
While I couldn’t verify cases of hallucination, I anticipate future models will improve to the point of flawlessly summarizing existing content. However, we’re not at that stage yet. Google’s AI Overviews have also been criticized for inaccuracies and fabrications.
Google seems to have swiftly addressed the problem, suggesting a potential decrease in hallucination occurrences.
A fundamental concern raised in plagiarism criticisms is that searching for an article’s exact title retrieves the article itself.
Naturally, Perplexity should generate article summaries upon user request. What other features should Perplexity offer? Similar debates arose in the OpenAI vs. NY Times lawsuit.
Apart from addressing the crawling issues that Perplexity needs to resolve, the media’s response appears to be influenced by Perplexity’s messaging strategy.
A key statement from Perplexity’s announcement of Pages encapsulates the core issue:
“In introducing Pages, we empower users to produce top-notch content without requiring expert writing skills.”4
Furthermore, the announcement highlights:
“Creating engaging content can be challenging. Pages simplifies this process by emphasizing clarity, breaking down intricate topics into easily understandable segments, catering to a wide audience from educators to business leaders.”5
The examples provided in the announcement all focus on instructional or explanatory topics such as:
These examples highlight the specific challenge AI poses to writers: AI is becoming increasingly capable of handling structured content formats like guides and tutorials. It’s understandable how this development could unsettle journalists and provoke their reaction.
Noticeably, Perplexity operates by utilizing human direction through prompts (UDC) rather than autonomously generating entire content for Pages. Humans contribute by assembling the content pieces and imbuing each Page with their authorial touch.
Looking forward, similar dynamics are likely to emerge across other content categories such as reviews on platforms like Google, Tripadvisor, Yelp, G2, and others. These platforms may introduce tools aimed at simplifying content creation. However, a major hurdle will be maintaining high quality and minimizing irrelevant information.
“The central question is whether a platform such as Pages can rival a purely human-authored site like Wikipedia, which currently boasts 116,000 active contributors.”6
In my opinion, the broader growth strategy behind Pages lies in Perplexity’s ability to transform summarized articles into AI-generated podcasts (video) that surpass original content.
“For instance, Perplexity distributed a derivative story to its subscribers via mobile push notification. It also produced an AI-generated podcast using the same Forbes reporting, without crediting Forbes. This podcast later became a YouTube video that outperformed all Forbes content on the same topic in Google search rankings.”7
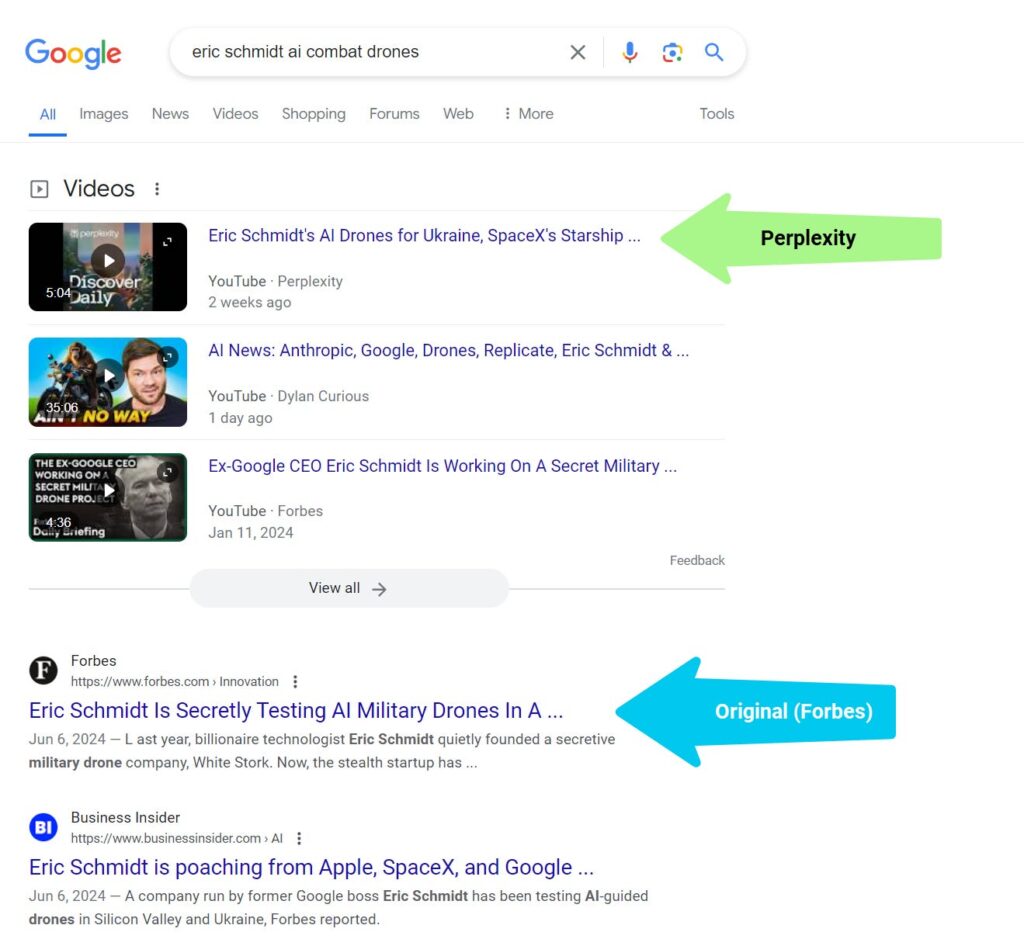
Google faces the challenge of preventing large language models (LLMs) from repurposing publishers’ content.
Upon closer examination, the difficulty lies in maintaining a balance: delivering comprehensive AI-generated answers while still directing traffic to original sources. The question arises: why would users click through when their inquiries are effectively answered?
Conversely, publishers can also contribute by providing summaries of their own articles. Hence, the primary hurdle for Perplexity—and any entity aiming to generate extensive AI content for Search—is to enhance the value proposition beyond mere AI-generated summaries.
Personalization is key to extracting unique value from AI summaries and other AI-generated content.
Imagine a system that understands your preferred depth of knowledge on any given topic; such personalized AI summaries would undoubtedly enhance their utility to you. While perplexity encapsulates various language models, its potential to gather substantial user insights and tailor outputs could significantly elevate its usefulness beyond mere rapid responses.
Operating system giants like Alphabet and Apple hold a distinct advantage due to their access to extensive user data, positioning them at the apex of the data hierarchy.
For instance, Apple’s intelligent systems could potentially replace current informational sources such as Google guides and Perplexity tutorials with responsive and comprehensive answers.
Apple Intelligence, cleverly abbreviated as “AI” by Apple, harnesses comprehensive context from diverse sources like location data from Apple Maps, usage patterns of third-party apps, prompts from Siri, emails from Apple Mail, and other inputs. This rich foundation enables personalized results tailored to individual users. While the web represents a vast repository of knowledge, a more intimate and compelling source awaits within our Dropbox, Gmail inbox, and iPhone photo library.
Currently, personalized answers remain aspirational concepts showcased in demonstrations.
However, looking ahead, personalized solutions are poised to outshine generic summaries generated by large language models (LLMs) and even surpass human-authored guides. The value of specific, personalized knowledge is on a collision course with the capabilities of LLMs. Concurrently, the worth of personalized insights, human experiences, and reliable expert advice is skyrocketing.
Original news from SearchEngineJournal


