
Last updated on

Researchers have discovered innovative techniques to prompt responses more effectively, as revealed in a study examining 26 tactics, such as providing helpful tips, that notably improve alignment with user intentions.
Outlined in a research paper titled “Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4,” this study delves deep into optimizing prompts for Large Language Models. Conducted by researchers from the Mohamed bin Zayed University of AI, the study involved testing 26 different prompting strategies and evaluating their impact on response accuracy. While all strategies yielded satisfactory results, some led to output improvements exceeding 40%.
OpenAI offers various recommendations to enhance ChatGPT’s performance. Interestingly, none of the 26 tactics tested by researchers, such as politeness and offering tips, are mentioned in the official documentation.
Anecdotal evidence suggests that a surprising number of users tend to employ “please” and “thank you” when interacting with ChatGPT, following the notion that polite prompts may influence the language model’s output. In early December 2023, an individual on X (formerly Twitter), known as @voooooogel, conducted an informal and unscientific test, discovering that ChatGPT tended to provide longer responses when the prompt included an offer of a tip.
Although the test lacked scientific rigor, it sparked a lively discussion and generated an amusing thread. The tweet included a graph illustrating the following results:
These findings prompted legitimate curiosity among researchers regarding the impact of politeness and tip offers on ChatGPT’s responses. One test involved eliminating politeness and adopting a neutral tone, avoiding words like “please” or “thank you,” which surprisingly led to a 5% improvement in ChatGPT’s responses.
The researchers employed various language models for their testing, not limited to GPT-4. They tested prompts with and without principled prompts to assess their effectiveness.
The testing involved multiple large language models to explore potential differences in performance based on model size and training data. These language models were categorized into three size ranges:
The following base models were utilized for the testing:
The researchers devised 26 distinct types of prompts, labeled as “principled prompts,” which were to be evaluated using a benchmark known as Atlas. Each prompt was tested against a single response for 20 pre-selected questions, with and without the application of principled prompts.
These prompts were categorized into five main groups based on their principles:
Under the category of Content and Language Style, several principles were identified, including:
In crafting prompts, adherence to six key best practices is paramount:
Below is an illustration of a test employing Principle 7, employing a method known as few-shot prompting, which entails providing a prompt containing examples.
When presented with a standard prompt, devoid of the principles, GPT-4 provided an incorrect response.
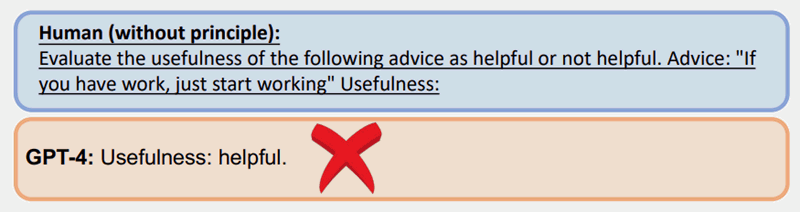
Conversely, utilizing a principled prompt (few-shot prompting/examples) for the same question yielded a superior response.

A notable finding from the test is that larger language models exhibit greater improvements in accuracy.
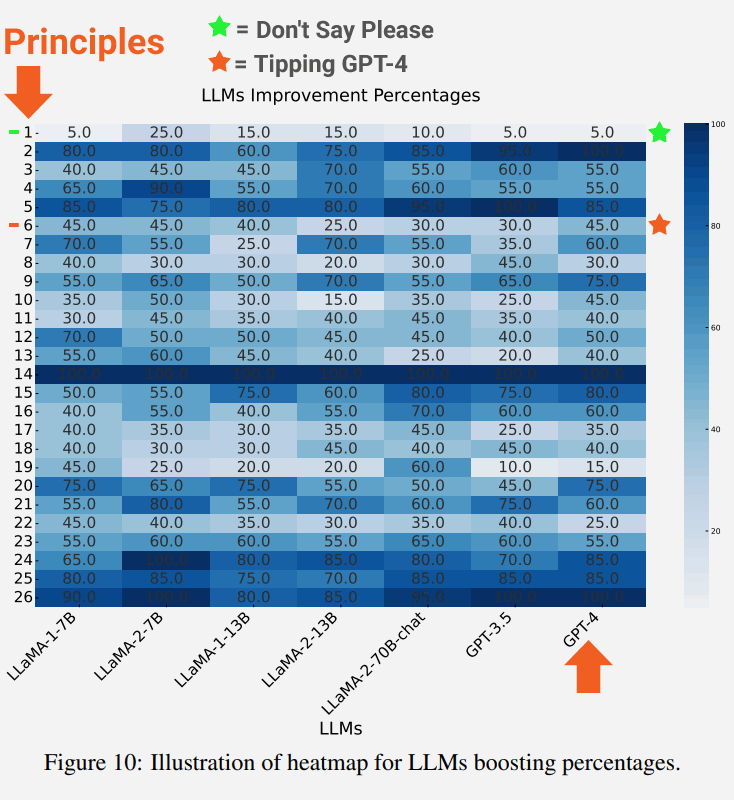
The provided screenshot illustrates the extent of enhancement for each language model concerning each principle.
Highlighted in the image is Principle 1, advocating for directness, neutrality, and avoidance of polite phrases like “please” or “thank you,” resulting in a 5% improvement.
Also emphasized are the outcomes for Principle 6, involving the inclusion of a tip offering in the prompt, surprisingly yielding a 45% improvement.
Description of the neutral Principle 1 prompt:
“If brevity is preferred, omit polite phrases such as ‘please,’ ‘if you don’t mind,’ ‘thank you,’ ‘I would like to,’ etc., and proceed directly to the point.”
Description of the Principle 6 prompt:
“Incorporate ‘I’m going to tip $xxx for a better solution!'”
The researchers concluded that the 26 principles significantly aided the LLM in directing its attention to the crucial aspects of the input context, consequently enhancing the quality of responses. They described this effect as “reformulating contexts”:
“Our empirical findings highlight the effectiveness of this strategy in reshaping contexts that could potentially undermine the output quality, thus augmenting the relevance, conciseness, and impartiality of the responses.”
The study also highlighted future research avenues, suggesting exploration into fine-tuning the foundation models using principled prompts to enhance the quality of generated responses.
Original news from SearchEngineJournal


