
Last updated on

If you’re an SEO practitioner or digital marketer reading this, you may have dabbled with AI and chatbots in your daily operations.
However, the real question is: how can you harness AI beyond just deploying a chatbot interface?
To truly leverage AI, it’s crucial to grasp how large language models (LLMs) function and acquire a foundational understanding of coding. Indeed, coding skills are becoming indispensable for SEO professionals aiming to excel in today’s landscape.
This article marks the beginning of a series designed to elevate your expertise, enabling you to utilize LLMs effectively in scaling your SEO activities. We foresee this skill becoming essential for future success in the field.
Let’s begin with the fundamentals. This series will provide essential information that empowers you to utilize LLMs effectively in scaling your SEO or marketing efforts, especially for handling repetitive tasks.
Unlike other similar articles, we’re starting from the end goal. The video below demonstrates what you’ll achieve after completing this series on using LLMs for SEO.
Our team utilizes this tool to expedite internal linking while ensuring human oversight.
Excited? Soon, you’ll be capable of building this yourself.
Now, let’s lay the groundwork by covering the basics and equipping you with the necessary background in LLMs.
In mathematics, vectors are entities defined by an ordered set of numbers (components) that correspond to coordinates within a vector space.
For instance, consider a vector in two-dimensional space, typically denoted by (x, y) coordinates as shown below.
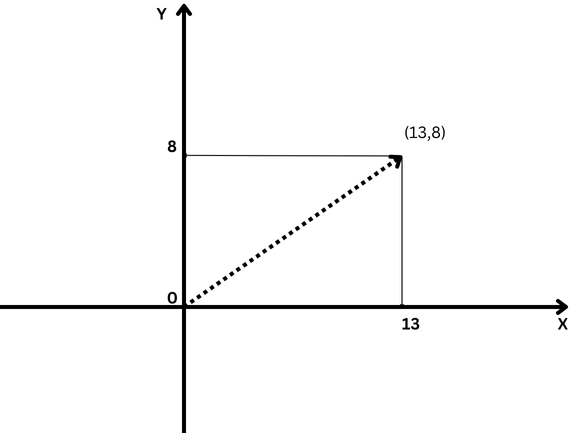
Here, the coordinate x = 13 represents the vector’s projection length along the X-axis, and y = 8 represents its projection length along the Y-axis.
Vectors described by coordinates possess a magnitude, also known as the norm or magnitude of a vector. In our simplified two-dimensional scenario, this magnitude is calculated using the formula:
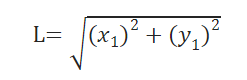
However, mathematicians have extended the concept of vectors to include an arbitrary number of abstract coordinates (X1, X2, X3, …, Xn), termed as “N-dimensional” vectors.
For example, a vector in three-dimensional space is represented by three numbers (x, y, z), which we can easily interpret. Beyond three dimensions, however, our ability to visualize becomes limited, and vectors transition into abstract concepts.
This is where LLM embeddings become significant.
Text embeddings are a type of LLM embeddings, which are complex vectors in high-dimensional space representing textual information. These vectors encapsulate semantic contexts and connections among words.
In the terminology of LLMs, “words” are referred to as data tokens, where each word functions as a distinct token. Broadly speaking, embeddings serve as numerical representations of these tokens, encoding relationships among various data tokens — which could be images, audio recordings, texts, or video frames.
To measure the semantic proximity of words, we convert them into numerical forms. Analogous to subtracting numbers (e.g., 10-6=4) where the result indicates the distance between 10 and 6 is 4, vectors can similarly be subtracted to gauge the proximity between two vectors.
Therefore, understanding vector distances is crucial for comprehending the functioning of LLMs.
There are various methods to quantify the proximity of vectors:
Each method has its own applications, but for this discussion, we will focus on the commonly utilized cosine and Euclidean distances.
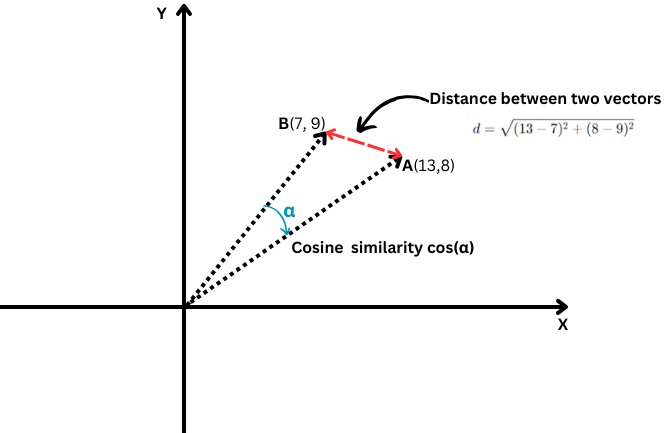
Cosine similarity measures the cosine of the angle between two vectors, indicating how closely aligned they are with each other.
Mathematically, it is defined as:
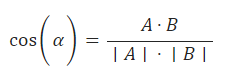
Here, the dot product of the two vectors (\mathbf{A}) and (\mathbf{B}) is divided by the product of their magnitudes (or lengths).
The resulting values range from -1, indicating vectors that are completely opposite in direction, to 1, which signifies identical direction. A value of 0 indicates that the vectors are orthogonal (perpendicular) to each other.
In the context of text embeddings, achieving a cosine similarity value of -1 is highly improbable. Instead, values close to 0 or 1 are typical. Here are examples where texts might exhibit cosine similarities of 0 or 1:
When comparing the texts “Top 10 Hidden Gems for Solo Travelers in San Francisco” and “Top 10 Hidden Gems for Solo Travelers in San Francisco,” their embeddings are identical. Therefore, their cosine similarity is 1.
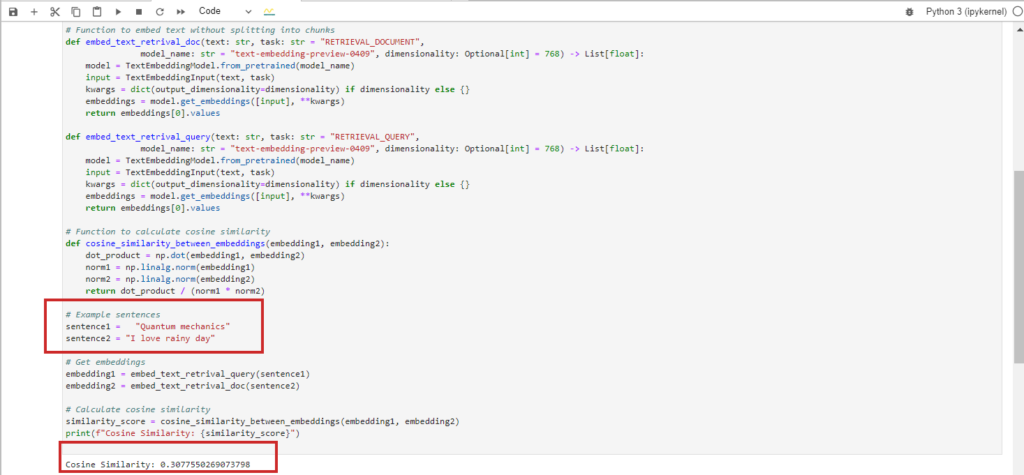
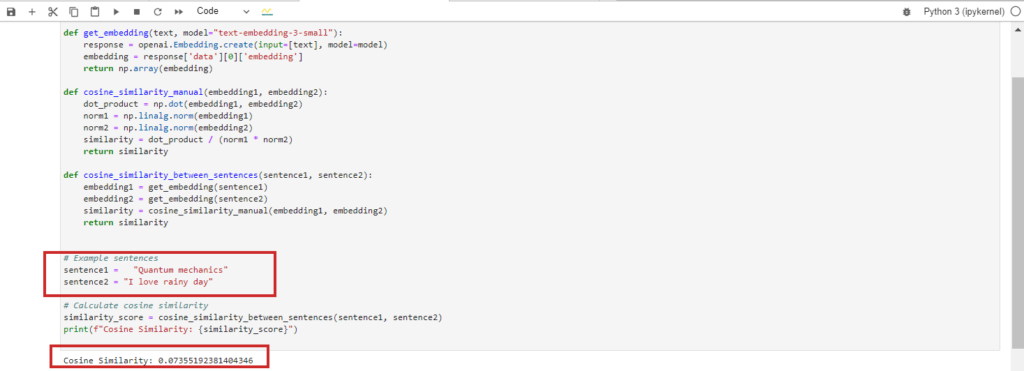
When comparing the texts “Quantum mechanics” and “I love rainy day,” they are completely unrelated, resulting in a cosine similarity of 0 between their BERT embeddings.
Interestingly, if you use Google Vertex AI’s embedding model ‘text-embedding-preview-0409’, you might obtain a cosine similarity of 0.3. On the other hand, with OpenAI’s ‘text-embedding-3-large’ models, the cosine similarity would be lower, around 0.017. These variations highlight how different embedding models can affect similarity scores due to their specific training and representations.
We are excluding the scenario where cosine similarity equals -1 because it is highly improbable.
When comparing text pairs with opposite meanings, such as “love” vs. “hate” or “the successful project” vs. “the failing project,” the cosine similarity typically ranges between 0.5 and 0.6 when using Google Vertex AI’s ‘text-embedding-preview-0409’ model.
This occurs because words like “love” and “hate” often appear in similar emotional contexts, while “successful” and “failing” are terms associated with project outcomes. These similarities reflect significant overlap in how these words are used within the training data.
Cosine similarity serves various SEO purposes:
Unlike focusing on vector length, cosine similarity emphasizes vector direction (angle), making it adept at assessing semantic similarity. This capability allows it to gauge content alignment accurately, even between content pieces of differing lengths or verbosity.
Future articles will delve deeper into each of these applications.
When you have two vectors A(X1,Y1) and B(X2,Y2), the Euclidean distance between them is calculated using the formula:
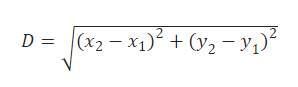
It’s akin to measuring the direct distance between two points (represented by the red line in the chart above).
Euclidean distance finds application in several SEO tasks:
For instance, a Euclidean distance value of 0.08 suggests minimal difference, indicating that content where paragraphs are merely rearranged would have a distance close to 0, implying near-identical comparison.
Certainly, cosine similarity can be utilized to identify duplicate content, typically with a threshold around 0.9 out of 1, indicating near-identical similarity.
It’s crucial to note that relying solely on cosine similarity may not be sufficient, as highlighted in Netflix’s research paper, which cautions against its use due to potentially producing meaningless “similarities.”
The paper demonstrates that cosine similarity applied to learned embeddings can produce arbitrary outcomes. This issue arises not from cosine similarity itself but from the inherent flexibility in learned embeddings, which can lead to arbitrary cosine similarities.
As an SEO professional, while it’s not necessary to fully grasp the technical details of such research, it’s important to recognize that alternative distance metrics, like Euclidean distance, should also be considered based on project requirements. This approach helps mitigate false-positive results and ensures more robust analysis outcomes.
L2 normalization is a mathematical process used on vectors to transform them into unit vectors, ensuring they have a length of 1.
To illustrate simply, imagine Bob and Alice have walked long distances. Now, we want to compare the directions they took. Did they follow similar paths, or did they head in completely different directions?
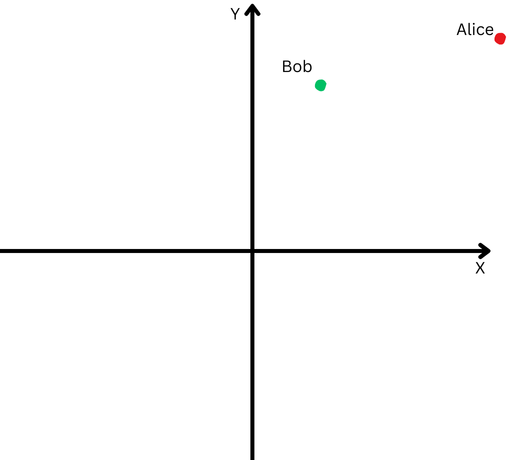
However, because they are far from their starting point, it becomes challenging to measure the angle between their paths accurately—they’ve ventured too far.
Conversely, just because they are far apart doesn’t necessarily mean their paths are different.
L2 normalization can be likened to bringing both Alice and Bob back to a closer distance from the starting point, such as one foot away from the origin. This adjustment simplifies the process of measuring the angle between their paths.
By applying L2 normalization, we can observe that despite their initial distance from each other, their path directions appear to be quite similar.
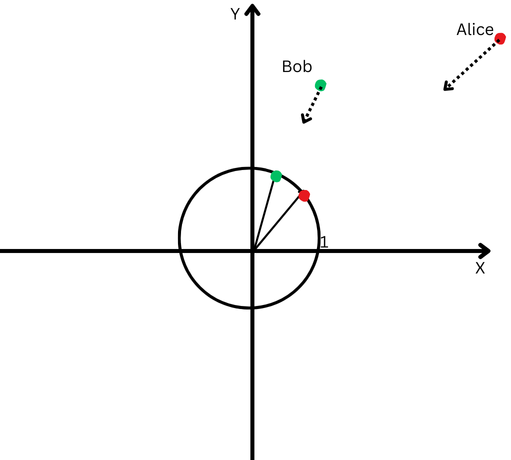
This process effectively eliminates the influence of their differing path lengths (represented as vector magnitudes), allowing us to concentrate solely on the direction of their movements.
In the realm of text embeddings, this normalization is crucial for assessing the semantic similarity between texts—focusing on the orientation of the vectors.
Many embedding models, like OpenAI’s ‘text-embedding-3-large’ or Google Vertex AI’s ‘text-embedding-preview-0409’, provide embeddings that are already normalized, obviating the need for additional normalization steps.
However, some models, such as BERT’s ‘bert-base-uncased’, do not provide pre-normalized embeddings and may require normalization before use in certain applications.
This introductory chapter aims to demystify the jargon surrounding LLMs, making complex information accessible without a PhD in mathematics.
If you find it challenging to memorize these terms, don’t worry. As we progress through subsequent sections, we’ll refer back to these definitions, helping you grasp them through practical examples.
The upcoming chapters promise even more intriguing topics:
Our goal is to enhance your skills and prepare you to tackle SEO challenges effectively.
While some may argue that automated tools can handle these tasks, they often lack the customization needed for specific project requirements.
Using SEO tools is beneficial, but developing skills tailored to your needs is invaluable!
Original news from SearchEngineJournal


